What: Run an LLM Locally with Ollama
If you’re curious about running a Large Language Model (LLM) on your own laptop — no cloud, no internet connection required — Ollama makes it surprisingly easy. It’s a simple way to use powerful open-source AI models directly on your machine.
Ollama is a developer-friendly tool that makes it simple to run Large Language Models (LLMs) like Llama, Gemma, or Mistral locally on your laptop with just a single terminal command. Ollama supports a wide range of open-source models and is used by developers, researchers, and privacy-conscious professionals who want fast, offline access to AI without sending data to the cloud.
Screenshot: Download the Ollama app, which gives a choice of open source models.
Why: Cost, Security, and Offline Access
There are two big reasons you might want to do this:
- Cost: You can run advanced models for free, with no usage caps or API fees.
- Security: Your data stays on your machine. If you’re working with sensitive info — tax returns, medical reports, or confidential client material — local AI gives you full control.
Other handy use cases:
- Using AI on a plane: No internet? You can still chat with your model mid-flight.
- Redacting private documents: You can use local AI to remove sensitive information before sending anything onwards to a more specialist public AI service, like ChatGPT.
When: Anytime You Want Full Control
Running a local model is useful:
- When you need privacy or data sovereignty
- When working offline
- When experimenting without worrying about cloud costs or limits
Who: People Comfortable with Basic Tech Tools
You don’t need to be a developer, but you should be:
- Using a reasonably modern and powerful laptop
- Comfortable downloading and installing apps from the web
- Okay using the command line or Terminal (you only really need to launch the Terminal app and paste or type a single command)
- On a decent internet connection (at least for the initial model download, which can be very large depending on how detailed you want your model to be)
💡 Enjoying this post? Subscribe to the newsletter for more insights on cyber, risk, and the hidden systems that shape our world.
📚 Or check out AI in 2027 — a look at a recent report predicting the impact of imminent superhuman AI over the next decade, and how it will be bigger than the Industrial Revolution.
How: Install and Run Ollama
1. Download Ollama
Go to https://ollama.com On a Mac, the initial download was a ZIP file (~176MB), which expands to a 451MB app (as at time of writing)
2. Choose a Model
Ollama supports a range of open-source LLMs, including:
- Meta’s Llama
- Google’s Gemma
- Mistral
- DeepSeek
- Alibaba’s Qwen
When you first install the Ollama app, it prompts you to install a version of the Llama model.
Each model has a different size. Larger models (more “parameters”) are generally more capable — think: single book vs. multi-volume encyclopedia vs. full library.
3. Run a Model
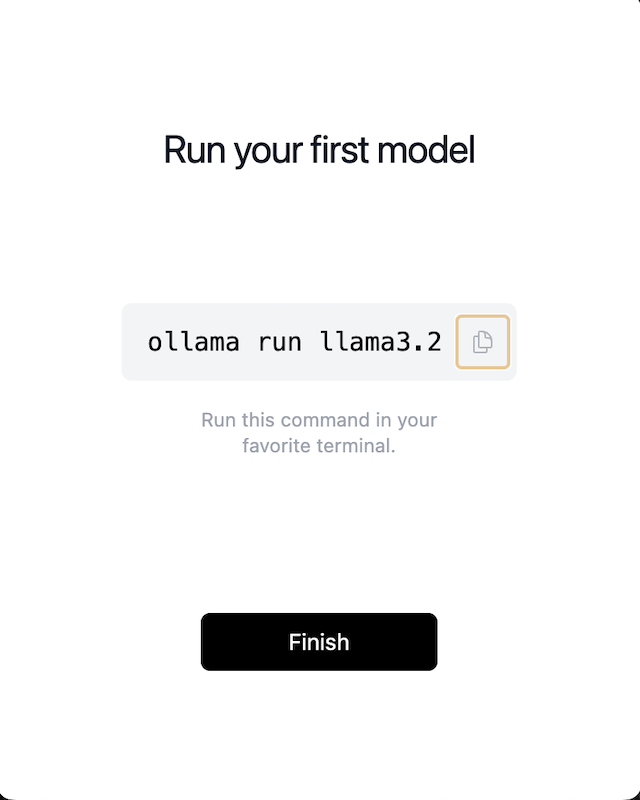
Screenshot: Terminal window showing the model being run for the first time.
Open your Terminal and run:
ollama run llama3
The first time you do this, Ollama will download the model (e.g. Llama 3.2 is about 2GB).
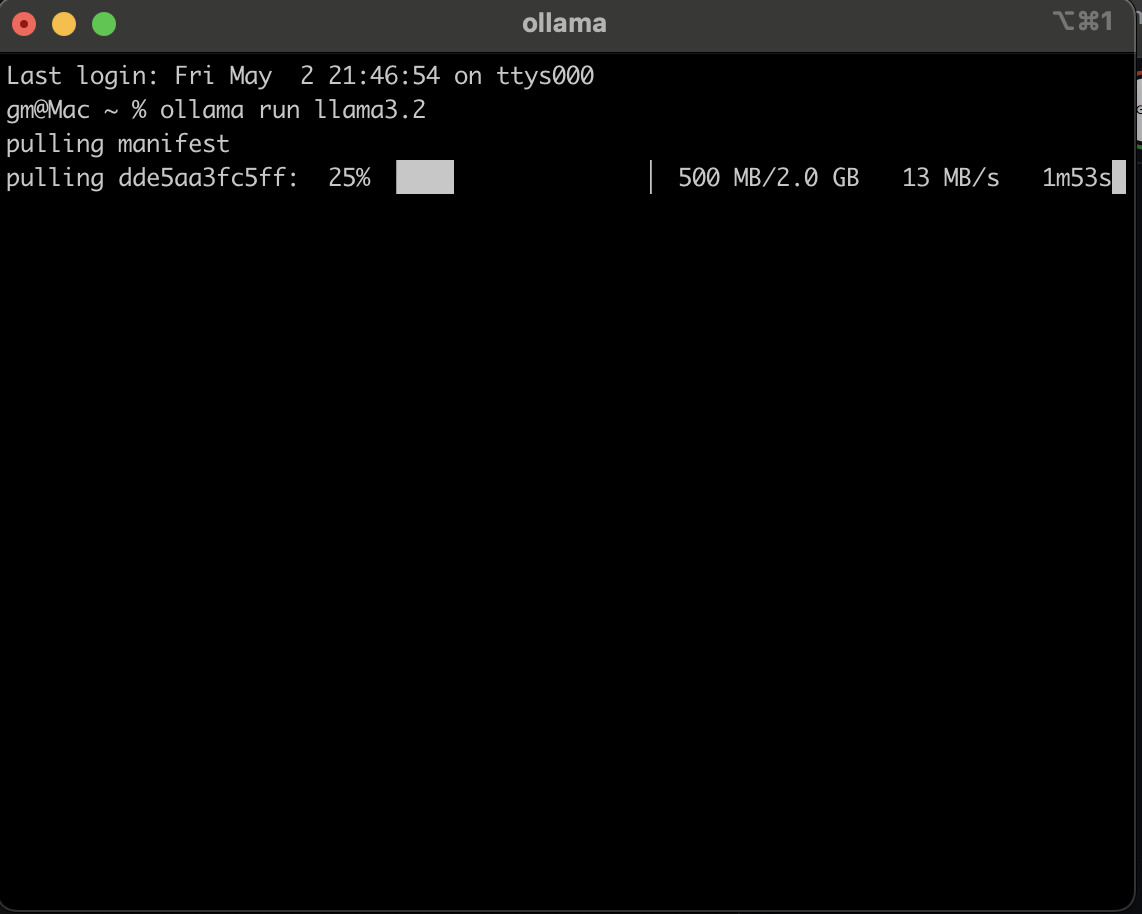
Screenshot: Terminal view of Ollama downloading a selected LLM to your local machine.
Once downloaded, the model stays on your hard drive — no need to fetch it again.
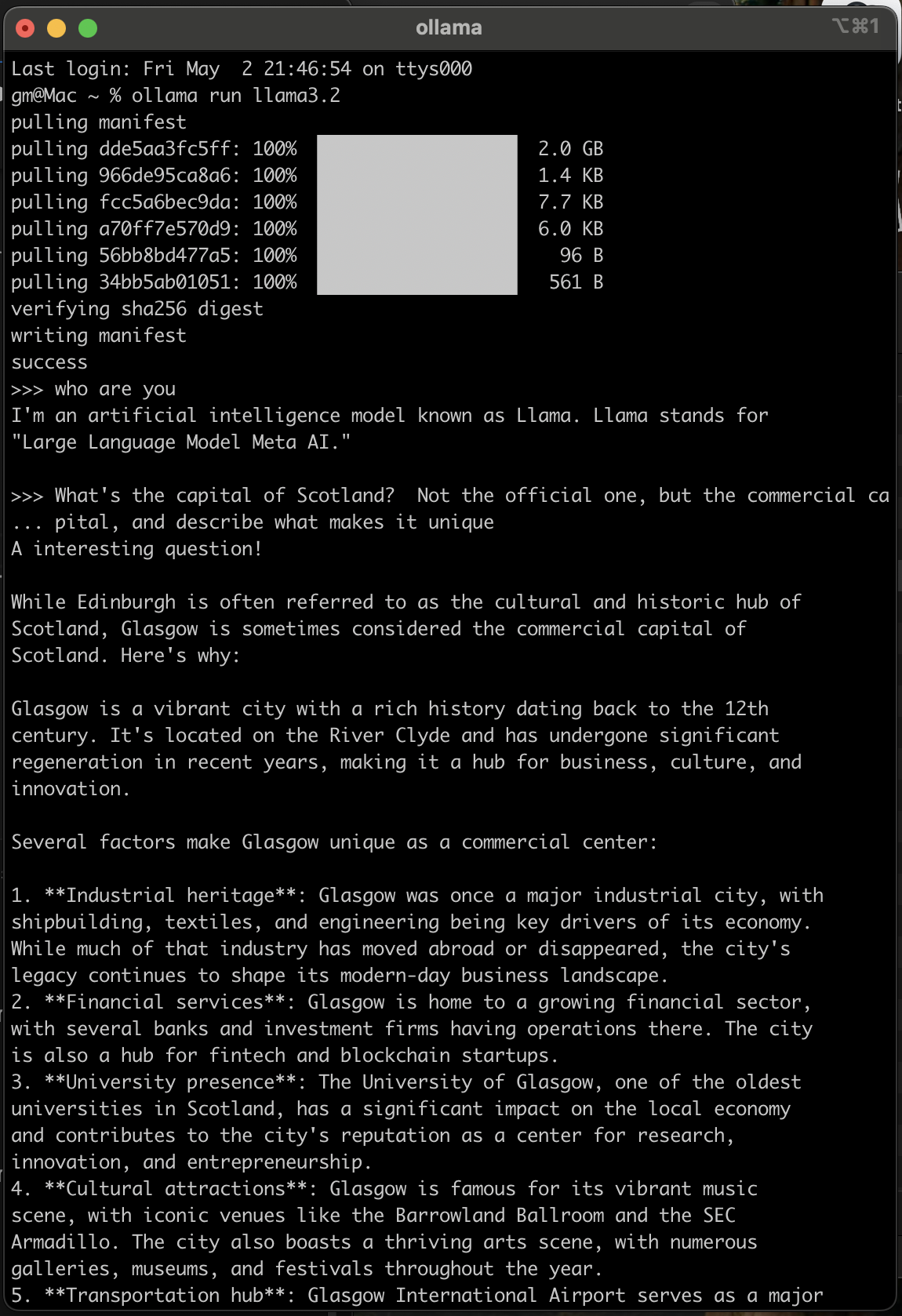
Screenshot: First interaction with the model — asking a thoughtful question in the command line interface.
Within a few minutes, you’ll have a chat interface running. That’s it. You’re live.
You can then use the same command on the terminal to download and test other models.
Screenshot: You can easily download other models, including Google’s Gemma model.
What’s Next: Upgrade the Experience
- Use a Web UI: To move beyond the command line, install a local Web UI that supports uploading documents, giving you a more visual and flexible experience.
- Add Retrieval Augmentation: You can set up your model to pull info from your own private files and notes. This is known as Retrieval-Augmented Generation (RAG), and I’ve written more about it here.